The Overlooked World of Managed Change
The Compliance and Security Series Part 2: Asset Management

by: Michael Wood
July 5th, 2022

The Dreaded Never-Ending CMDB
I met with a brand new CISO at a large healthcare company, and we discussed several ways to improve the defense posture of his systems along with a few modern patterns for improved audit and control. While he agreed with the approach, he felt powerless to do anything in the near term. “Why is that?” I asked. “Well,” he began, “I’ve started an inventory of what we have. We don’t have any visibility of what infrastructure and applications are running, much less their risk position. So, we are now going account by account, line of business by line of business doing an inventory.” “Wow! How are you going about this, and how long do you think it will take to assess your environment?” “The primary method is to go to the director level and ask them to report on their cloud accounts and pull the data we need. Currently, we are estimating six weeks to complete. Once I have a picture of what we are dealing with, we can start to work through a strategy.”
I don’t know why this caught me off-guard. This pattern is so common we often joke about the ‘never-ending content management database’ projects that have been a dream in IT for … well, as long as I can remember. The CMDB aspires to answer a central demand of enterprise IT, especially regarding governance and security: I have to know what I’m working with to propose any sort of optimization or governance. The obvious flaw in this asset and risk management approach is that it’s a moving target in such a way (ask people to self-report) primarily because the report is out of date by the time it is submitted (much less at the end of a six-week effort). The only way to call the data collected ‘complete’ would be to force all teams to stop changing their environments for some time.
As I mentioned in the previous article, you cannot manage what you cannot see or understand.
Demands of Standards Bodies
To bring this back around to the goals for governance imposed by government or industry standards bodies, we will again review the NIST CSF (Cyber-Security Framework). In particular, we’ll focus on the Identify function.

Before we can start evaluating advanced patterns of defense (like the infamous “zero-trust networking”), we have to find a way to cleanly identify trusted resources in general. Under the Identity function, areas of focus include Asset Management, Governance, Risk Assessment, Supply Chain Risk Management, and similar. To re-emphasize the truism that we cannot defend what we cannot see or understand, we must start with understanding our environments. The biggest challenge to managing assets centers on manual or wildly disparate modes and methods of provisioning.
To ensure consistency of terms, asset management is simply documenting IT assets that our teams are leveraging. Beyond the basics, however, we are also interested in metadata about the asset. We need to be able to answer questions like “what OS is that asset running?” And “what assets are running this vulnerable scripting library?” Generally, NIST recommends the use of something like an ITAM (IT Asset Management) solution to help house this information, but that data is only as valuable as it is current. If you consider SolarWinds Service Desk, Vanta, or similar services, these packages will need read access to all cloud instances in order to mine for this information, or it will need manual updates for anything off books, physical or otherwise inaccessible to the tooling (air-gapped data center assets, etc.). Even as we look at this kind of record-keeping, we are perpetually working to catch up to reality.
Record-Keeping at Scale
So how do we get current? Or, better yet, can we get proactive? The challenge is that the rate of change in our environments continues to accelerate. These data sets and additional IPs needed for overlay tools to scan my environments for rogue assets are themselves sensitive systems that require audit, control, and security. Even with an ITAM that scans the environment (say, at night when user experience is least likely to be impacted), we find we are getting a skewed picture of our environment. Auto-scaled assets are spun down to near dormant states, for example. Once again, I add complexity over the top of existing complexity to better manage the environments that I am responsible for. Naturally, I want to try to think differently about this challenge.
A primary driver for this scanning is due to what I will refer to as ‘unmanaged change.’ We mostly practice “click-ops” style systems administration (a user on some tool’s dashboard making manual changes), or perhaps we are scripting in pockets and motes. Many organizations will have Salt, Puppet, Perl, Bash, CloudFormation, vRealize Automation, Docker Swarm, Ansible, open-source Terraform, and a dozen others all introducing changes in various ways to various scattered tech stacks. While the automation is better from a throughput standpoint with slightly better promise for audit, it still introduces tremendous gaps in our ability to understand anything at scale. So how do we think through asset management in order to create a clean(er) approach to the introduction of change with audit and asset management in mind?
As I mentioned in the previous article, I favor intention-driven approaches to IT management. An operator (developer/engineer) will declare what state they want/need for the infrastructure. That intention can then be vetted for compliance, cost, security, and other demands of the business. In accordance with the demand for clean asset management from the start, this process should also update ITAM in real-time.
Decorating for Better Control and Responsiveness
For anyone new to this space, infrastructure as code (IaC) is the term for defining executable intent for the state of infrastructure. This intent is then fired through an engine to convert intent to reality. There are a couple of subdivisions in this space, namely between configuration management tools (which tend to be procedural) and configuration languages like HashiCorp Configuration Language (HCL), which are declarative. The differences can be nuanced but also lend themselves to different advantages. There are comprehensive comparisons between the two approaches (and how they work together) in other places, so I won’t belabor the point here. While I recognize the differences in approach and the various players in the space, I’ll focus on what I see as the unique approach to declarative infrastructure management with something like Terraform.
Terraform conducts infrastructure updates via a multi-stage approach. In brief, an operator or system builds or triggers an existing build of an infrastructure declaration. This declaration is fed into the Terraform engine which first conducts a plan phase. In this phase, Terraform evaluates the existing state of the infrastructure and returns a series of steps that the engine will take to make what was asked for into reality. Originally, this phase allows an operator to look over the prescribed changes, and if all looks correct, then the operator commits the changes through a Terraform apply command. Progressively, we are seeing a tremendous amount of automation against this plan output.
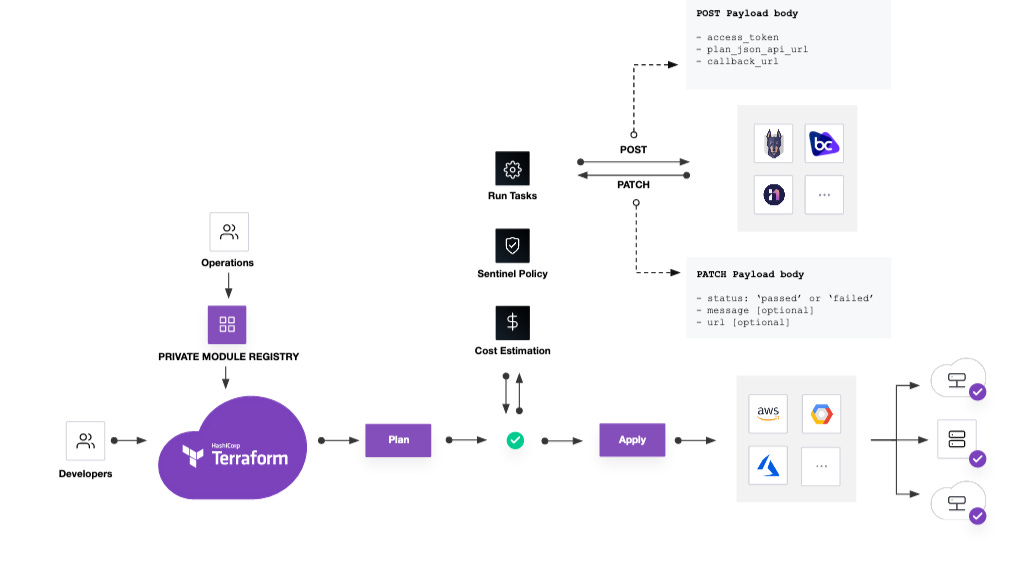
In the above diagram, we are illustrating that same workflow with a couple of additions that become incredibly useful at scale for teams and enterprise-wide leverage. Up towards the beginning of the diagram, the need for a registry of available assets with access control helps improve the reuse of pre-built infrastructure modules. The goal, in this case, is to reduce the heavy cost of ‘distributed toil,’ or the requirements to constantly re-write infrastructure code. The other result of consuming known modules is that (by definition) we know the outcome. In terms of asset and risk management, this is greatly preferred to manually configured one-off assets. As we jump ahead into future write-ups, we can get very concise on chain-of-custody, access controls, and several other elements that are important to our overall defense and audit posture, but for now, we will stay focused on asset management.
The second point of augmentation to the basic Terraform workflow is our automated audit gates post-plan. Once Terraform has assessed the infrastructure state and returns the instructions it will conduct to make the ask real, we have an outstanding opportunity to automate all audit functions. Initially, this included basic cost estimation (to conform to GRC cost expectations) as well as a full policy-as-code engine called Sentinel. Through this policy-as-code engine, we can provide an initial scrub of the environment for security (CIS libraries, for example), observability (proper asset tagging), and pretty much any other standard we wish to require (lockdown Kubernetes, no publicly accessible storage, etc.). All of these outcomes help drive greater trust in our initial assessment of our newly provisioned environment.
As we continue to mature in this space, Terraform has added an element called Terraform run tasks. These are essentially webhook functions to allow callouts to external systems to gain even more control over delivered assets. In addition to policy and cost assessment, perhaps we want a risk assessment. With a quick call to Brodgecrew or Snyk or some other source scanning tool, we can assess the relative risk associated with packaged open-source elements and make a determination on whether we will release the code to production based on that risk.
Other uses for this call-out mechanism would include updating our ITAM system of record. If we need a consistent (near)real-time view of deployed infrastructure, then a centralized workflow to assess all elements of the infrastructure roll complete with an update to our system of record provides us with the cleanest approach to accomplishing this task. When we need to ask questions about our infrastructure, we have the ability to include all of this data. Your records should include chain-of-custody (who requested, credentials), telemetry (dates, times, state, region, tags, types, etc.), policy gates cleared and approved, the risk associated with the code assets, and much more.
Now, I’ve had a few conversations about asset management in more real-time (i.e. state changes due to auto-scaling, etc.) that may not be captured through a Terraform deploy. There are some interesting discussions to be had around service management and mesh as an additional way to understand the current state with regards to those elements, but we will save that for a later discussion.
Trust through Attestation
This begins to open up a world of implications as it relates to risk management. This automated approach yields not only day 1 benefits, but unlocks the possibility of continuous and evolutionary capabilities to our implementation of managed change. Once we have defined the expectation for the state of our infrastructure, we can trigger this automation in response to events (change in network routes, etc.), but in terms of this topic we have the concept of environmental ‘attestation.’ What if we digitally sign assets as an additional ‘proof’ that they were manufactured in the appropriate way? What if we then trigger a ‘re-attestation’ of the environment, and rotate the credential as part of that re-assessment?
Part of the need for the concept of continuous attestation is the prevention of unauthorized changes outside of the process, but we can use these processes to go a step further and ‘repave’ environments continuously. That is, if we continuously (or on regular intervals) deploy a known good state with audit, policy, etc., to replace the existing infrastructure, we are in effect perpetually cleaning our infrastructure. This impacts our continuing expectation of trust in the assets under management and greatly limits the potential of persistent threats - those attack vectors that require prolonged access to environments. In effect, we continuously remove barnacles that grow in unmanaged environments.
Continuing Evolution
Naturally, this is the tip of the iceberg. As we automate the delivery of infrastructure, we unlock all sorts of potential for securing and managing our technical real estate in countless ways. As we begin to turn to access management, credentialing, data classification and encryption, perimeter defense, and the numerous other elements of cyber-security, many of these ideas will come back here for implementation. For secrets management, as an example, how can I automate and centralize the issuance and revocation of secret materials while removing human intervention? Well, I just might be considering embedding secrets dynamically via an automated pipe similar to the above.
To that end, the next write-up will dive into identity and access management in earnest and look at how we simplify and reduce the cost of a few best practices.
Until next time!