

Field CTO Newsletter: The Half-Life of a Secret.
Volume 113

“Most secrets are secrets of the mouth. Gossip shared and small scandals whispered. These secrets long to be let loose upon the world. A secret of the mouth is like a stone in your boot. At first you’re barely aware of it. Then it grows irritating, then intolerable. Secrets of the mouth grow larger the longer you keep them, swelling until they press against your lips. They fight to be let free.
Secrets of the heart are different. They are private and painful, and we want nothing more than to hide them from the world. They do not swell and press against the mouth. They live in the heart, and the longer they are kept, the heavier they become.”
- Patrick Rothfuss, The Wise Man’s Fear
Secrets. It’s a word that never fails to dredge memories from my past. Vivid flashes of schoolyard crushes, the whispers of confidence shared, and gut-wrenching fear as my desires and hopes were held up in the light for all to see. Patrick Rothfuss had it right - secrets fight to be let free.
As humans, part of building relationships is demonstrating vulnerability with each other. We share little pieces of ourselves and, as we build intimacy, ever larger pieces. We exchange secrets, and trust is born. Over time, more friends know your secrets and in some strange way, they evolve into shared history. They are no longer secrets, but stories to remember together around a campfire, or while playing cricket in the backyard.
I find it interesting that these accepted behaviours among humans run so counter to how we expect technology to behave. Vulnerabilities are to be exploited, relationships are transactional, and trust… well, these days trust becomes zero-trust. The one thing that remains constant is the use of secrets and how the person (or system) that knows the secret inevitably ends up sharing it.
While researching for this post, I found an interesting paper from Ruth Nelson. The whole paper makes for good reading, but there was one section that particularly caught my eye (emphasis mine).
One "common sense" definition of a secret is some information that is purposely being kept from some person or persons. It is interesting to investigate the behavior and characteristics of secrets; this can lead to doubts about secrets being easily defined objects. It can also lead to some understanding of the limitations of any automated or unautomated approach to keeping secrets, for secrets cannot in general be kept absolutely. In the broader security community, this is fairly well understood. The goal is to keep things secret for some amount of time, or to make secrets hard to obtain, or to slow down the leakage of secrets. In computer security, however, we ignore considerations of this kind, and we try to design systems that have high assurance of not leaking secrets at all. This leads us to some very difficult technical problems, but may not be leading us to greater system security.
- Ruth Nelson, 1994, What is a Secret and What does that have to do with Computer Security?
Again comes the idea that secrets cannot remain secret, that over time they degrade, often to the chagrin of companies and their customers.
The Medibank breach was a big deal here, the loss of 9.7 million current and former customers’ data triggering the Government to make changes to Australia’s penalties for the Privacy Act, and it all began with a secret that became not secret.
“We believe ... one [set] of our credentials was compromised, but we've got an ongoing investigation into exactly what happened."
- David Koczkar, Medibank CEO
Nelson’s idea of degradation over time led me to compare the decay of secrets to radioactive decay. The Center for Disease Control describes radioactive decay as “the process in which a radioactive atom spontaneously gives off radiation in the form of energy or particles to reach a more stable state…. Half-life is the length of time it takes for half of the radioactive atoms of a specific radionuclide to decay. A good rule of thumb is that, after seven half-lives, you will have less than one per cent of the original amount of radiation.”
Can this idea of shedding radiation until virtually none is left in the original material somehow be applied to secrets? Do secrets shed confidentiality over time? Do secrets have a half-life, and how can we measure it? Let’s begin by defining the term “secret” in our computing context.
Secret (n): A confidential piece of information used by a single entity (person, system, application, service etc) to authenticate to another entity.
If we were to share that secret with a second entity, have we just halved the confidentiality of the secret? If you share a secret with someone else, then they share it with two other people, who each share it with two other people…. before you know it, everyone in Year 2 knows about your crush on Michelle White and you are hiding behind the demountable at lunchtime. Ahem.
People are fallible, and so is software. The more entities who know a secret, the greater the chance of accidental (or intentional) misuse - committing credentials to a repository, sharing a Powershell script with embedded credentials, leaving a screen unlocked with an API token on screen while fetching a coffee, storing a private key in a world-readable folder, the list is long. As my mate Andy Murphy says, “for each person greater than 1 the chances of a f***-up increases exponentially”.
The second factor we need to consider is time. How long will it take for a secret to be shared? A secret that has not changed in five years is far more likely to be shared or compromised than a secret that has not changed in five minutes (all other factors about usage being equal). The amount of time you would be comfortable betting against a secret being shared or compromised is likely relative to how sensitive any target environment or system is that you can use that secret to access. In that sense, time becomes a leading indicator that a secret will shed confidentiality while the number of entities with access to the same secret becomes a more concrete trailing indicator.
“The problem is not that there are problems. This problem is expecting otherwise and thinking that having problems is a problem.”
- Theodore I. Rubin
To take Theodore’s advice, how can we shift our thinking to accept that any secret in our organisation will move through its confidentiality half-life, and become compromised? If this is the new normal, what can we do to take the risk out of this happening? What if…. what if we could look at how many entities had access to a secret, how long since it was last rotated, what operations you could perform if you had the secret, and how sensitive the environments were that the secrets granted access to? Could that be used to identify how much confidentiality had been shed and allow us to take appropriate action? What if we could go one step further and revoke or rotate credentials automatically, in your code, environment variables, or configuration files?
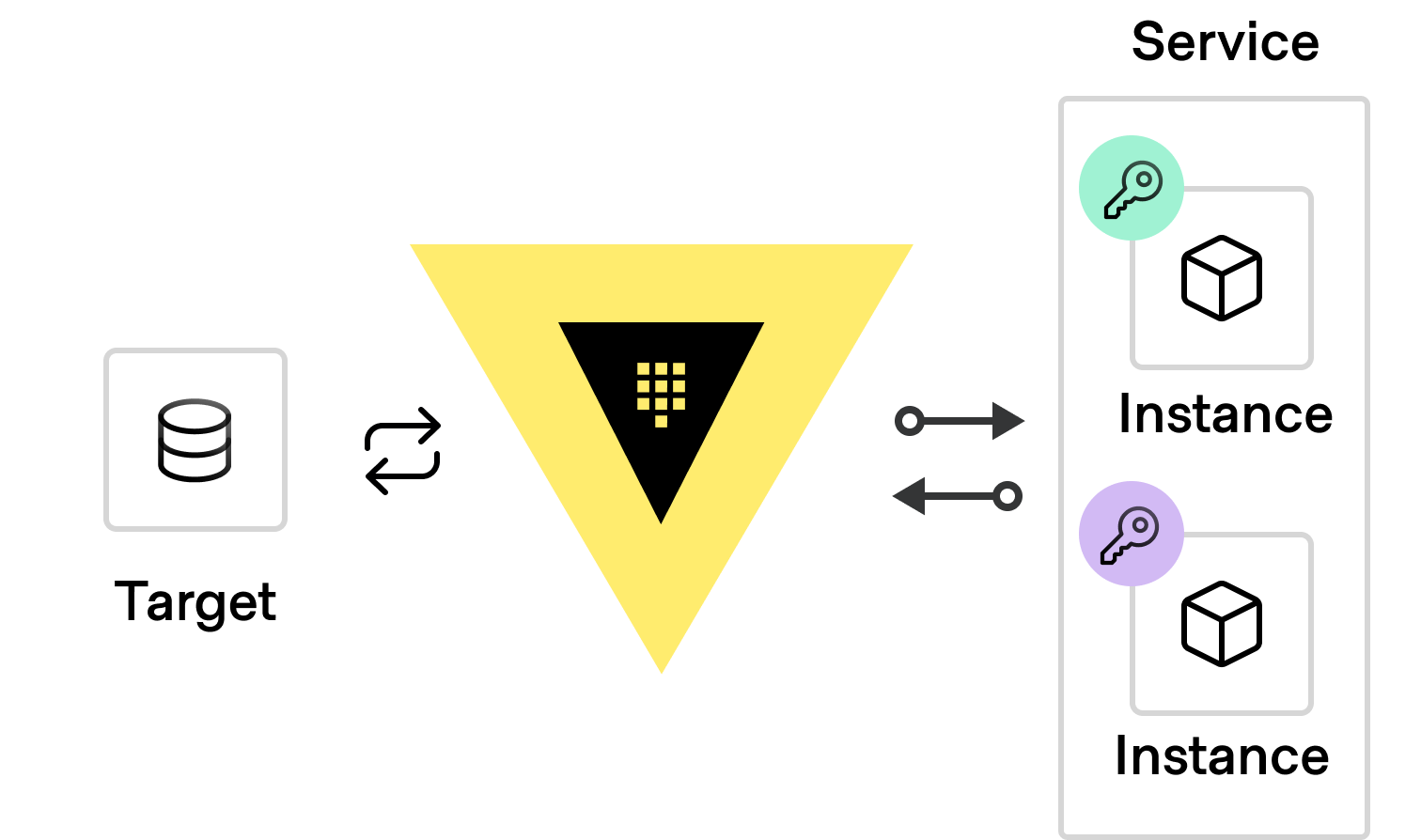
Figure 1: Two instances of a service requesting and receiving unique, time-bound, on-demand secrets from Vault to authenticate to a target service.
Creating time-bound secrets with automated lifecycle operations for revocation and renewal is one of the core principles of HashiCorp Vault. You tell Vault how long you are comfortable with allowing a secret to remain valid, and it will generate them on-demand for target systems, rotating or revoking them as needed at an application or system level. Each request results in a unique secret, so secrets are never shared between entities. This behaviour is often described as “dynamic secrets”, but there is a depth of nuance that this moniker misses. Time-bound secrets, managed secrets, automated secrets, secure secrets? Maybe some things can’t be distilled into a simple label, though if you have any ideas I’d love to hear them.
Rather than getting hung up on labels, let’s look at a recent example where the value of tightly scoped secrets proves their value. The recent CircleCI breach was a pretty nasty one, and before we go any further I need to say that the transparency and communication from CircleCI were top-notch. Many customers I have spoken with since the breach shared that they needed to manually revoke and generate new secrets for many systems, and then pass them back to their hundreds or thousands of pipelines. Engineering teams worked nights and weekends to ensure those leaked credentials were useless. A much smaller set of customers shared how little engineering work was required to mitigate this breach because they had embraced our paradigm of short-lived secrets - generating them through Vault at the start of a pipeline run, and then revoking those same secrets through Vault when the run finished. This closed-loop model for secret generation, usage, and expiry is incredibly powerful. The same model can be applied to operator sessions and credential management, although maybe I’ll save that for the next newsletter.
While the ecosystem around Vault is unparalleled, it would be remiss of me to not acknowledge that there will inevitably be some secrets that need to be stored as static values in a more traditional key/value (KV) store. In that case, secrets aren’t guaranteed to be unique per entity since they aren’t generated on demand. In the case of KV secrets, we need to fall back to our two confidentiality half-life indicators. First, how many entities have access to this secret, and second, how long is it since it was last rotated? Let’s deal with the latter first.
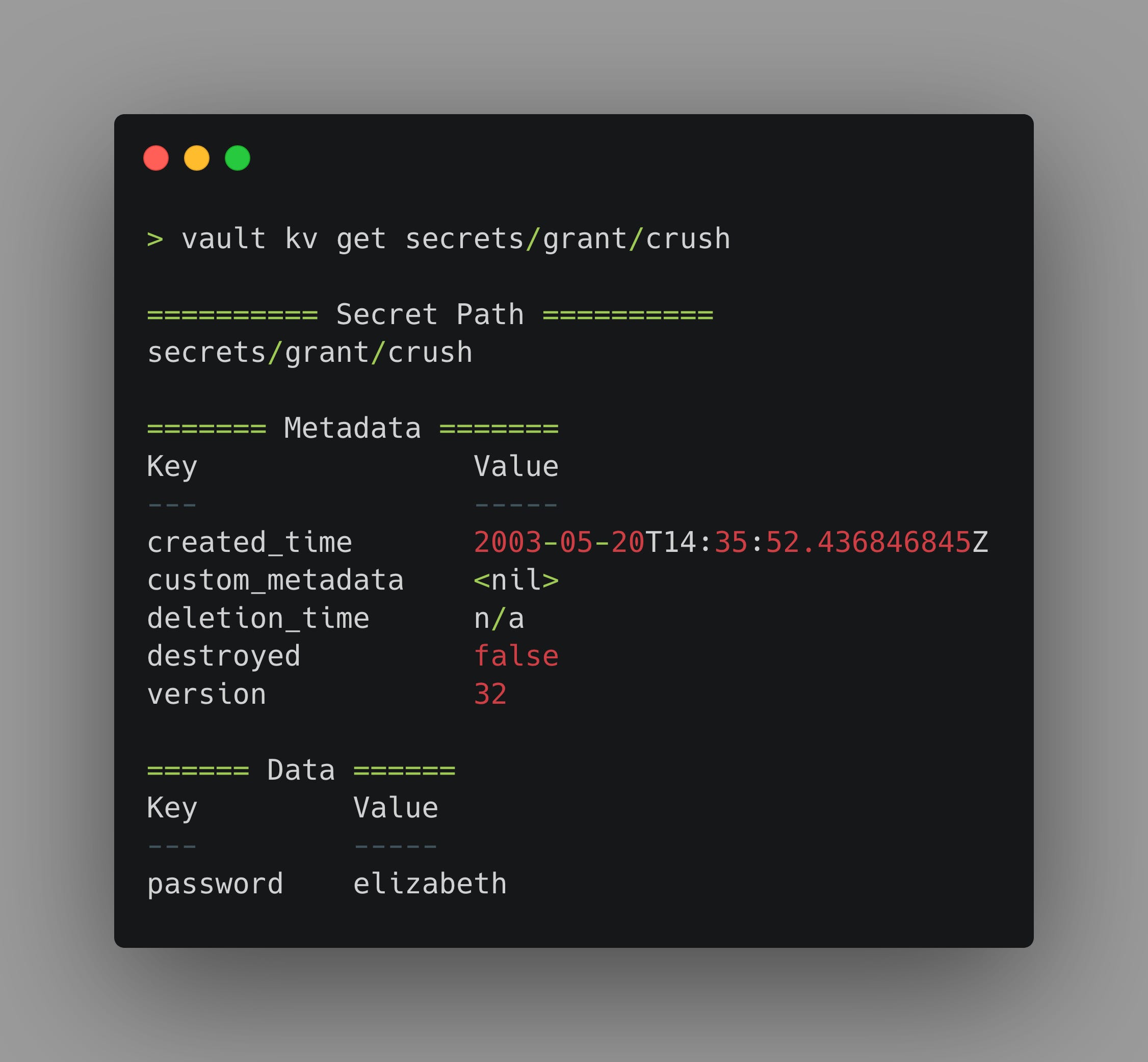
As you can see from the creation_time, my crush on my wife probably needs to be rotated, but you don’t need to mention that to her.
The created_time attribute is specific to a given version of a KV secret. So if I go back and look at version 1 of this same secret, we will see a different timestamp.
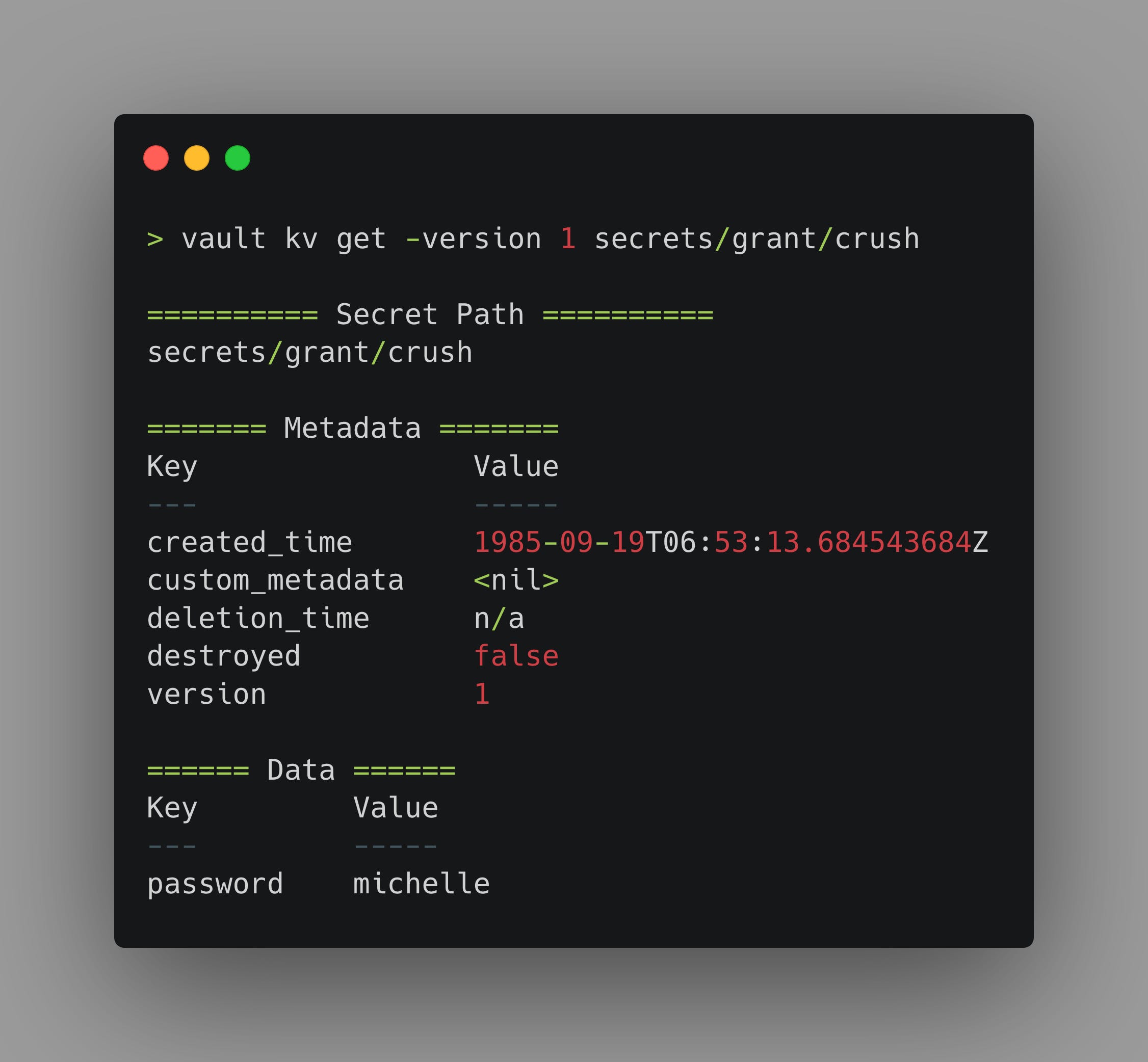
In a real-world scenario, you will want to use the vault kv metadata get command, so you can assign a policy that limits access to secret metadata and doesn’t permit whoever is auditing creation dates to access your secrets.
Like our dynamic secrets engines, KV secrets can be queried in application code, or watched with the Vault agent and rendered into files or environment variables. This means you can update a KV secret centrally in Vault, and have it rotated automatically on the systems and applications using it.
As for checking how many entities have accessed a given secret, we can take advantage of Vault’s audit logging capabilities. In most enterprise organisations these will be forwarded off to a monitoring platform with the ability to generate alerts and notifications on these kinds of events, but on my local setup, I have to make do with using jq to parse my logs.
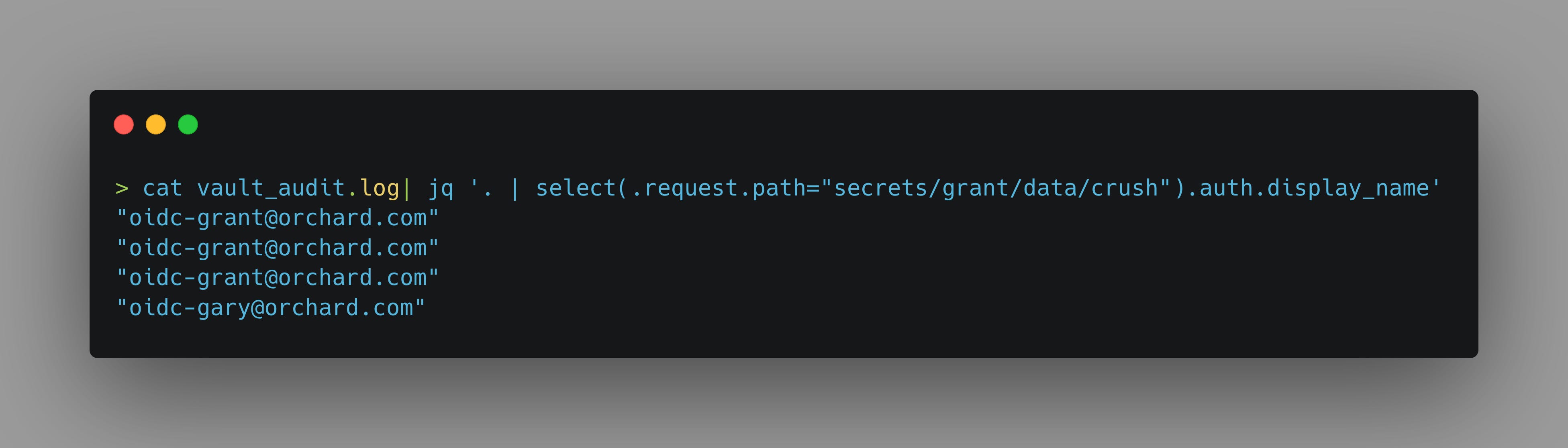
What I’ve done here is select any log entries that match the path to the KV that I want to assess, and then return the display name associated with the request from the results. As we can see, Gary has access to my crush secrets (which is bad) and I can dig further into the audit log to get information about which policies grant the requesting user access to the secret. Armed with the age of my secret, and the number of entities who have accessed it I can begin to evaluate how likely it is that my secrets are still secret and consider the risk associated with that.
So, there you have it - the half-life of a secret. Wouldn’t it be nice to ask Vault for these kinds of insights and get a dashboard that showed us the half-life of our secrets? Maybe, hopefully, someday.
Footnote
Ruth Nelson’s comment about slowing down leakage reminded me of an episode of Bluey where our courageous heroine attempts to stop the rainwater coming out of the downpipe from making its inevitable path down the driveway. I couldn’t find a way to weave that into my story today but figured it deserved an honourable mention.

I won’t spoil the finish, since I know you’re all going to go and watch it (Season 3, Episode 18 - you’re welcome).