FCTO Weekly Newsletter: Challenges to Change are Human
Models for Self-Service through Platform Teams

Welcome!
It has been a few more days than usual since our last newsletter, and this one may be a little different than usual. While we generally pick on the recent news and provide some perspective, this episode is more of an aggregation of observations working with many of our largest customers, especially regarding platform teams. I wrote this with a great friend (Nick Young) who worked with one of these customers on their implementation. Thank you, Nick! I love working with you!
As we look at the world of IT, change is a never-ending force. In most of our efforts to affect how we measure and manage digital change, we sometimes decide on tools first and then try to fit the org to the tool. For example, we may decide to use Salesforce for CMM, then we decide how to structure everything to fit how SFDC expects things to work. We occasionally adopt a tool to see if it can force a change to a better human model, but you get the point. Here, we will play with how we structure a team to drive against our automation goals.
For this newsletter, let’s look at successful self-service automation models in large companies doing incredible things. I’ll have fewer references, as much of this contains observations from companies we directly or indirectly worked with. I’m still very tempted to dig into how Elon, Obama, and Kim Kardashian got hacked, but we’ll save that for another time. (It would be fun, though!)
The Challenge of Change is Human
OK, stop me if you’ve heard this before. An IT team decides to deliver a new approach to automate IT service (network, infrastructure, security, application), so they spend a year building a better mousetrap. The mousetrap is, in fact, miles better than prior approaches, but something odd happens. Adoption is underwhelming, complexity emerges that frustrates early movers, and ultimately the desired improvement washes out. The company resumes normal pre-change operations, wasting lots of money and time on a failed implementation.
This scenario happens more than we want to admit. As change agents, we strive to push the boundaries for improved efficiency, yet most writing for DevOps teams centers on technology outcomes rather than people outcomes. In this write-up, we will endeavor to show a few different team structures that have proven successful at scale in maximizing results (and, therefore, adoption) as they introduce changed processes and automated delivery.
Platform Team: A Thought to Change Introduction
Given we do not lack access to technology or tools, it behooves us to consider humans as the primary friction to change and think through how to improve our methods for engaging people. I recently sat down with a brilliant CTO in Houston, discussing the nature of tech debt. The conclusion we reached was that debt primarily resides between our ears. If we cannot see a path to success, we would prefer to stay where we are, safely numb to our inefficiencies.
How, then, do we map a way to change that avoids the pitfalls of forced or disjointed efforts that routinely fail us in the enterprise? Well, we’ve tried two pizza-balanced teams, DevOps, SREs, centers of excellence, innovation centers, and more. Today’s ‘hotness’ is the “Platform Team.” I have to say I love the tech hype machine! Everyone in operations now has the title ‘platform engineer,’ which is fascinating. The job didn’t change, but the title certainly did. Better to have that on the resume this year, it seems. Additionally, everything seems to be important to the Platform Team. For example, QE Unit describes how QA supports the platform team, and Humanitech discusses where Platform Engineering is on Gartner’s hype cycle (enhancing their ideas around developer platforms). I intend not to exhaust you with all the organizations driving platform engineering into every company’s IT discussion, but rather to indicate that nearly everything can be part of that team’s purview.
Naturally, the core idea around a platform team is rooted in recognizing the need to centralize commonly leveraged core IT services to deliver digital experiences. As the cloud marketplace has forced enterprises to consume overwhelming complexity at a pace we’ve never seen, the common refrain is to centralize and industrialize delivery: Reduce and contain complexity through automation. How do we do this in an enterprise? The pattern is to commission a team to drive that effort.
Failures arise from many vectors. The top few to immediately come to mind include:
Forcing change before the team is ready. In the early days of implementing new delivery methods, teams will push change too quickly and before they are ready. This leads to early frustration that causes initial adopters to abandon the effort.
Build it, and they will come. Engineers are not always well-versed in sales and marketing, but without a plan to drive consumption up front, underwhelming adoption leads to frustration and funding questions.
Lack of goals and measures. Without a goal, automation spirals in dozens of directions, leading to new complexity replacing the old.
In another post, I’ll take some time to find answers to these challenges. Still, the platform team requires a measured way to introduce change for consumers and the organization to support the chosen approach. In this first pass, we’ll investigate approaches to platform team structure based on the outcomes we hope to achieve. These functioning models provide ideas and guidance around tradeoffs between these three shapes. The three models portray some level of maturity that organizations can grow through, but they also will give a view into scale and tradeoffs. Generally, organizations begin with an Insourcing Model that may eventually give way to more of a Community Model. When the organization wishes to extend the automation to less technical team members, we may adopt a super opinionated PaaS-style abstraction (I’ll refer to it as Full-Auto). Let’s break each of these down.
The Insourcing Model
The first platform team structure is a bit easier to implement with adoption. Most development teams request the change through tickets. Why not just go with that? Don’t ask development to change their approach to anything. Just implement the automation behind the ticket; otherwise, leave consumers alone. Hey! Great idea! As you move towards centralized automation, I would advise taking this approach if you currently operate behind the interface of tickets. As you start building tooling, it does not matter if a human is behind the ticket implementing the automation on behalf of a requesting team. Ultimately, the ticket time is coming down as the automation matures.
Here at HashiCorp, we have customers at a substantial scale with this model. An enormous retailer leverages a 50-person platform team to service requests from thousands of developers. The team’s efforts on tooling, then, serve themselves. Their goal is to respond to tickets quickly, and the measures for the team revolve around that effort.
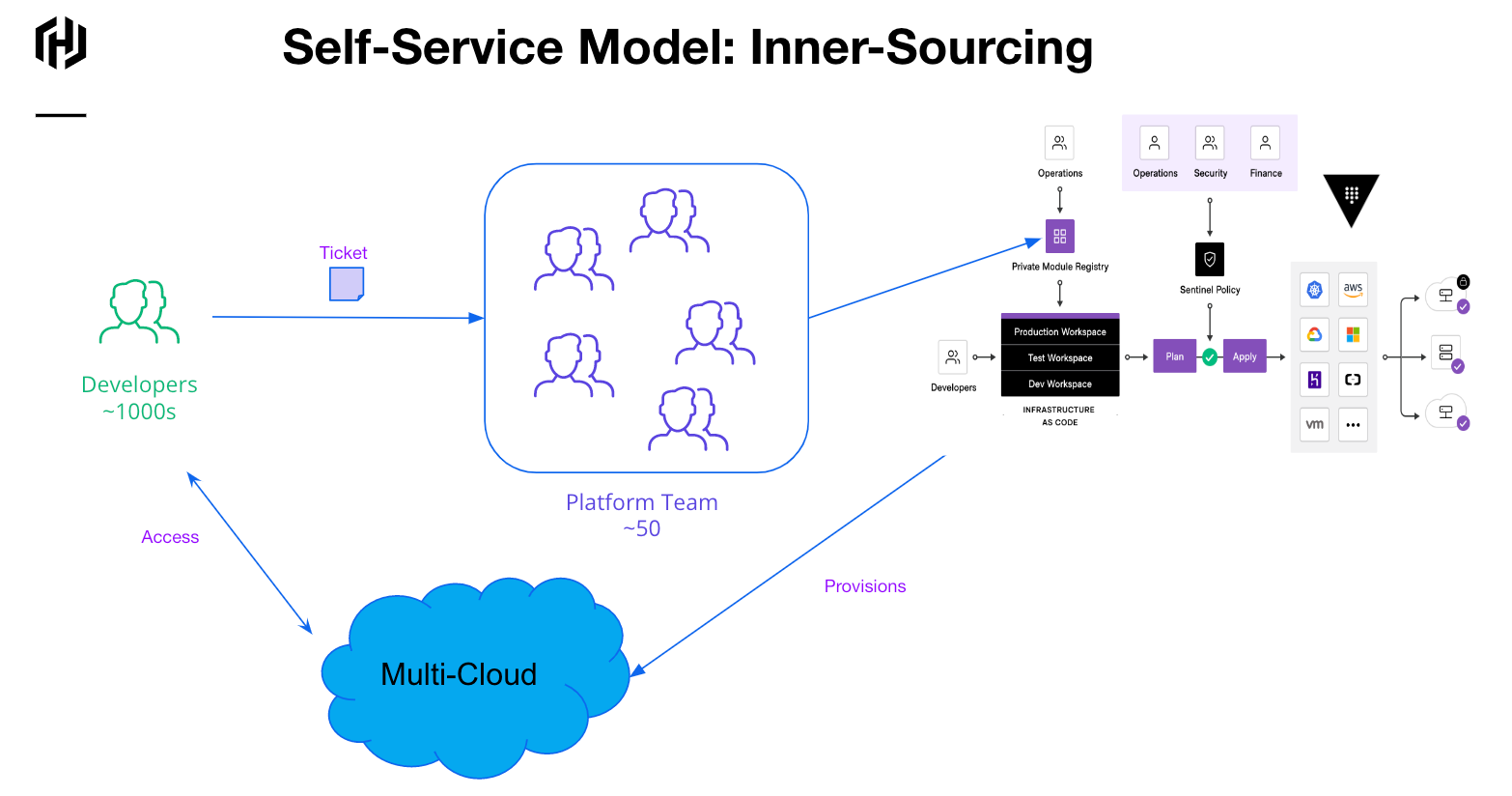
Cons for this Platform Team structure:
A larger team
On average, slower response times than the others discussed here
(Mostly) Traditional separation between development and operations.
That is, the platform team operates, and devs are abstracted.
Pros for this Platform Team:
Minimal disruption to consumers.
Lowered enablement efforts for the enterprise.
Change is hidden from consumers.
As we consider costs for this team, we are erring on the side of a more expensive platform team instead of distributing those costs across the larger IT org. We still have a well-governed infrastructure but do not change many folks outside the core team.
The Community Model
A large insurance provider supplies an incredible example of our second structure: the Community Model. They began their automation journey through an ‘acceleration’ team, which constituted the beginnings of what we now call a “platform team.” Their initial ambitions included locking down DevOps toolchains, dynamically handling identities, simplifying audits, and reducing manual operations. However, the company wanted to drive a DevOps culture throughout IT with a different approach from the first model. They moved quickly from an inner-sourcing model into a community-supported model.
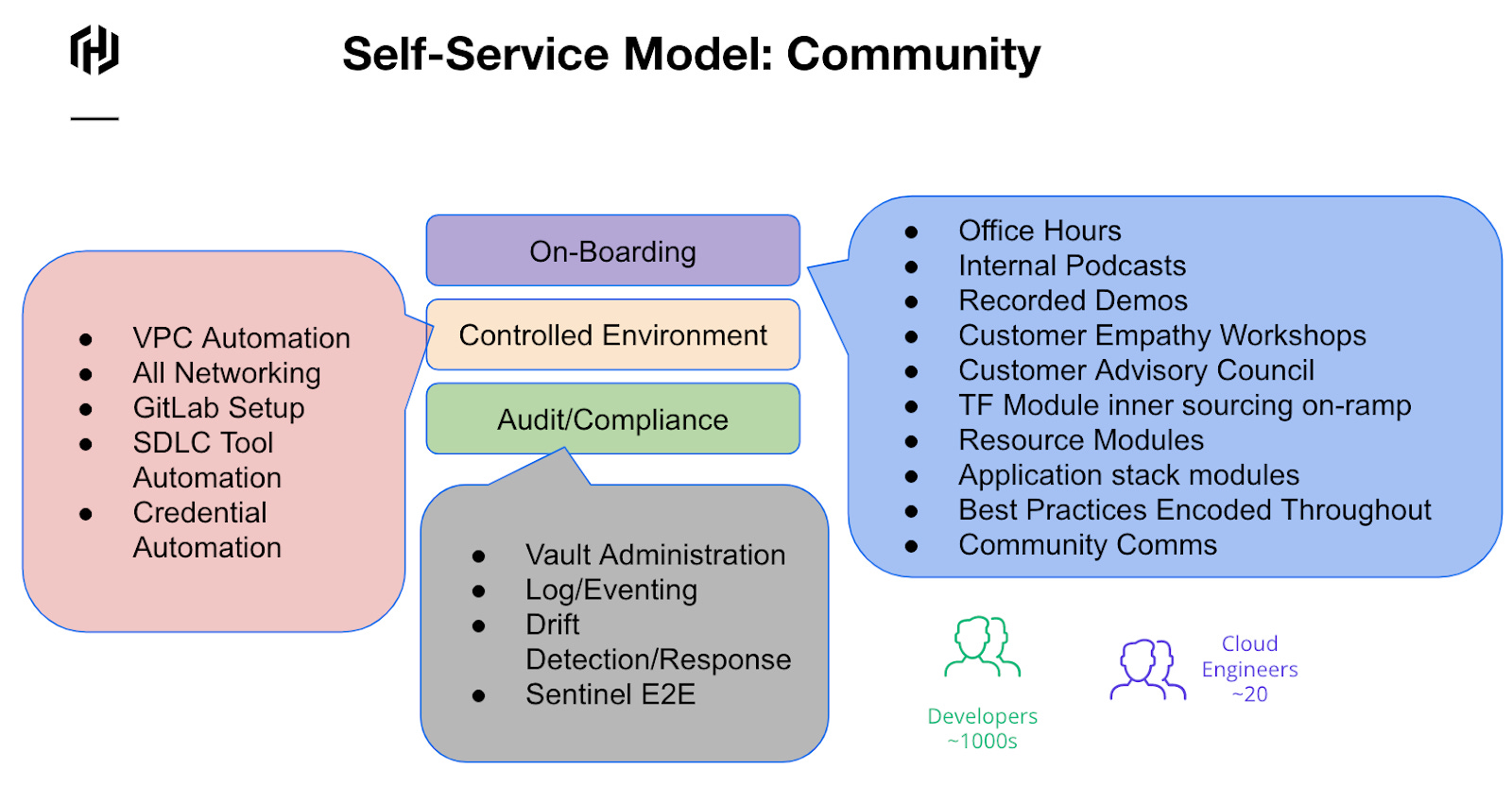
In this model, we lean on the side of widespread enablement. The goal is to bring the entire organization to curated cloud adoption. To accomplish this goal, the platform team focuses on automation that provides guardrails and removes certain elements from the developer’s purview. These elements include protected resources like the network, DevOps tool configurations, accounts in third-party tools, secrets management, log management, observability, etc. This method also drives more flexibility for development teams to craft their environments.
To make this happen, we err on the side of robust onboarding. The carrot is that you must first onboard if you want to move to the cloud. Onboarding ensures new teams learn to request environments, learn to ‘DevOps,’ get added to community collaboration spaces, and provision automated and vetted environments. Developers are then free to declare the infrastructure required.
In terms of measures, we know that the community approach distributes the automation culture throughout the company. The big event that indicates the platform team has hit a tipping point is when the community begins answering questions for the community. In effect, developers begin helping developers on board and succeed with automation. Then the platform team’s SREs can shift focus more fully on new automation and platform ops. Other measures to watch for are more SRE-related (outage budgets, resiliency measures, cost) and looking to reduce onboarding time for new users.
The cons of this structure include:
Heavier cost in training and onboarding
More detail exposed to developers
The pros of this structure:
Smaller team than inner sourcing (think ~20 platform engineers to 1000s of developers)
More freedom for developers in their environments
Everyone participates in dev/ops
The “Full Auto” Model
Like the retailer’s goals, a large digital media firm sought to remove as many automation details as possible from their users. Instead of doing this through a ticket, they constructed a graphical user interface that interacts with their automation chain of tools. In this approach, no human exists between the developer and their environment.
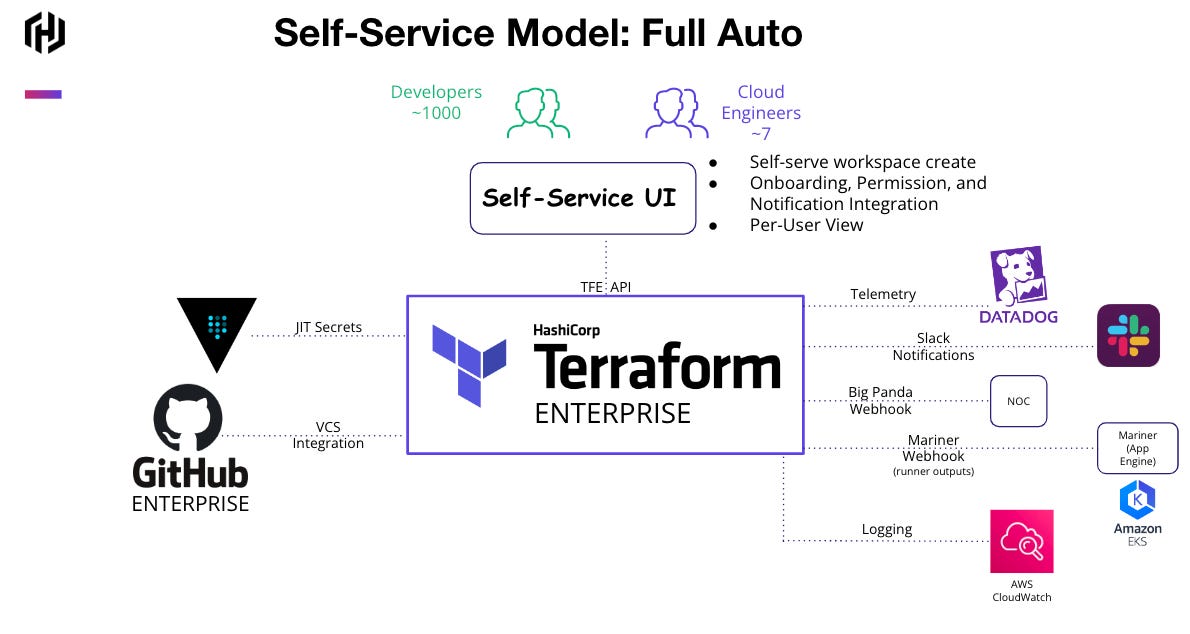
Generally, the profile of this platform team consists of a lean set of highly technical engineers that have to support a developer organization at the rough scale of 1 platform engineer to 100 developers. Three imperatives are non-negotiable at this scale:
Focus on the outcome - A developer is immediately onboarded consistently, quickly (measured in minutes, not days), and appropriately scoped to the cloud platforms and environments leveraged by their respective team.
Manual tasks must be automated and obscured by the developer. This means investing in automation by leveraging the APIs of any underlying systems necessary to reach the above outcome.
Security is embedded into the workflow, not an afterthought - This means the platform team proactively allocates a percentage of resources dedicated to security collaboration, remediation, and improvement efforts.
Infrastructure provisioned through this workflow proactively checks for compliance before provisioning, and pre-approve infrastructure modules come with first-class support from the platform team.
When considering the pros and cons of building a UI, it may help to understand the long-term implications of the approach and the goals and objectives of your organization. The profile of these platform teams varies depending on their core focus. There is a contrast between an organization focused on “investing for the future” or “cutting costs.” When executed correctly, an organization like this media firm cultivates a culture of investing for the future. The bi-product has been exponential savings across operational, security, and cloud costs.
The pros of this structure include
Very high leverage on platform engineers (~7 supporting over 1000 devs).
Uniform and secure baseline infrastructure resources with associated RBAC controls.
Quicker time-to-productivity given the lack of exposure to most complexity.
In-line, objective policy enforcement with an instant feedback loop makes developers and information security teams confident that the infrastructure provisioned through this platform is compliant before it instantiates.
In the cons category, let’s consider this is where the platform team will invest the majority of their resources. Responsibilities include
Heavy upfront resource investment in developing and testing the initial versions of the UI.
Enhancing and updating the UI when underlying APIs get added, changed, or deprecated.
Small changes carry heavy and widespread impacts and must be evaluated carefully.
Break/Fix and troubleshooting issues that may reside beneath the UI abstraction that a developer can not rectify themselves.
Conclusions
All three approaches can yield tremendous improvements over traditional ITIL/ITSM ticket-driven operations. However, their mileage varies based on your objectives. The Inner-Source Model should work well if the objective is to change as few people as possible. If you want folks to change some but maximize your automation (stripping most choices from the developer), then the “Full Auto”/PaaS Model may be ideal. If you aim to invite everyone into new skills and a new culture, then the Community Model is the way to go.
In practice, large, mature organizations will have a blend of these approaches. They may start inner-source, then shift to Community after establishing a few successful deployments. After establishing momentum and enriching automation, the team pivots to providing a greater abstraction for less technical audiences. The team will eventually provide different abstractions for different user cohorts. This rundown aims to expose the trade-offs so that as you embark on your journey towards self-service facilitated by a platform team, you may align the structure to the outcomes you wish to drive.