

Introduction
As the reality of multi-cloud and cognitive load continue to apply pressure to application delivery and IT operations, the emergence of Platform Teams and centralized delivery of core IT services appears unavoidable. As an industry, we continue to attempt to walk the fine lines between numerous forces: freedom, control, compliance, speed, resiliency, efficiency, availability, and more. To do so, we drive standards into our coding and delivery practices, that has the potential to become very inconsistent at scale. We also end up challenged with platitude leadership styles. For example, “Who’s responsible for security? Everyone’s responsible for security!” While notionally true, it is impractical against our counter platitudes, like, “If everyone is responsible, then no one is.” So how do we make decisions when we often work at counter purposes to ourselves?

At a high level, we begin by drawing distinctions between teams and what they take ownership of. According to Zscalers latest Cloud (In)Security Report:
Under the current directive, cloud security and compliance are shared responsibilities between the cloud service provider (CSP) and the customer. This is known as the Shared Responsibility Model. While CSPs provide security for the cloud service and hosting infrastructure, the customer is responsible for managing security policies, access, and data protection within the cloud. Understanding the shared responsibility model and proper account configuration is important for helping enterprises align and effectively implement the right compliance and security policies.
While Zscaler observes that a lack of understanding of shared responsibility leads to potential gaps in security best practices between the CSP and the customer, this lack of shared service ownership also impacts how we interact across IT departments. As mentioned above, security takes center stage in the “who owns that” sweepstakes. Credentials are owned by devs, code repos, DBAs, service providers, key stores, and more. Service certs for mutual TLS are owned by devs, CAs, SaaS services, various third parties, the service mesh du jour, Kubernetes, and more. Who issues these credentials? Under what conditions? Do we allow developers to own their secrets (generally using cloud-native services)? Do they fully grasp what the cloud owns and what they do?
While the switch to Dev/Ops made developers responsible for everything, implementations became so bespoke that managing fleets of unique deployments became untenable, especially in the face of ever-changing cloud infrastructure services, methodologies, cyber-attack vectors, etc. And what happens when we need to change our approach to something broadly? Do we go team by team asking for changes? “Hey, everyone, I know our standard initially took this approach to mutual TLS, but we’re going to suggest a different architectural approach …” Is the expectation that everyone adapts quickly, cheaply, and perfectly?
The idea behind brokerage aligns with the thinking that centralized delivery of core services allows the enterprise to standardize and optimize change delivery. While we do not aspire to align brokered services around specific technologies (as we did in ITIL/ITSM style models), we seek consistency around the job that needs to be done. For example, rather than having tickets for F5, CheckPoint, PANW, Alkira, Arista, Cisco, Dell, NSX, AWS, Azure, etc., we would have brokered delivery of networking full-stop. How would I do that same thing for identity? Infrastructure? The question, then, becomes, “What is the interface?” We’ll dig into these thoughts in more detail below.
The Concept
Brokerage is a fairly common concept in the business world. Individuals may use a financial broker to access a portfolio of financial assets, or health insurance claims will be adjusted and aggregated through a broker on behalf of an insurer so the insurer can consolidate payments in compliant ways. We also engage tax professionals to help us deal with government filings where the laws are so complex and difficult to understand that we need a professional who focuses on dealing with all that noise. These brokers help keep us safe, legal, and optimized.
In a fully brokered IT environment, the aim is to provide an automated yet brokered response to requests by developers or operators. In traditional IT operations, we have a ticketed but manual process orchestrated around ITIL/ITSM-prescribed workflows. We augment these efforts with robust ticketing systems like ServiceNow, but comprehensive IT modernization demands automation. The type of brokerage discussed here implies a general pattern in which a consumer submits some form of intent, that intent is vetted, and then automation delivers the requested changes in downstream systems.
As this approach becomes ubiquitous, all changes happen solely on fully vetted contractual interactions. Much as one would provide a financial broker with assets who would then create contracts and manage financial investments on your behalf based on pre-established criteria, a brokered IT ecosystem receives an intention and leverages a series of assets, such as identity, networking, infrastructure, and application delivery with predefined policy to create the IT environments. As these systems become more complex and intertwined, organization and structure become even more critical.
To implement a fully brokered environment, instead of thinking about point-to-point systems interaction (for example, IT grants access to native cloud services to get work done), the focus moves to how teams should request changes in an abstract sense. How does a developer express their intended changes at the infrastructure level? In their applications, the intent is defined in code. They submit changed code to a source control system where validations take place, and (in modern shops) actions are triggered to scan for vulnerabilities and build and deploy (via CI/CD) the new application resources. But how are secrets managed? How is infrastructure updated? What about the risks of misconfiguration?
To dig into these topics, we begin at the infrastructure tier.
Brokered Infrastructure
As the industry pivots towards platform teams as a product, we must clearly shift our thinking around infrastructure delivery. Given the complexity of our IT world in a multi-cloud scenario, with thousands of reusable services at our fingertips, we have a choice on how we govern such an estate. First, we can hire people to watch tools that watch people that watch tools that watch people, which is a fairly typical, expensive, and reactive response. Or, we can have infrastructure changes requested via policy-enforcing workflows. To provide the latter, we think of a platform team that broadly provides an infrastructure provisioning service for the enterprise.
In essence, I want my consumer to request the desired changes in a way that both the infrastructure service and the development team can understand. That intention is vetted for compliance, security, cost, risk, and whatever else we need before being approved for implementation. In addition, identities provide my trust gates along the way. The user who made the ask needs to have been vetted, of course, but so should the systems involved. The job also benefits from an identity that restricts what systems it can or cannot touch. For example, a job slated for our “test” environment should have no rights to “production” data sources. I’d also prefer this service to do its best to understand that once an environment is instantiated in a compliant way, the infrastructure service maintains that compliance by preventing drift.
A mature platform team is critical in the IT infrastructure brokerage process. Still, it requires that the team understand the technology, the producer's capabilities, and the consumer's objectives. They must understand how intentions and strongly vetted identity contracts provide the foundation of a trusted environment for IT service consumption. The platform team becomes the centralized brain that understands the cloud shared-services model. The contract clearly defines responsibilities between teams.
By brokering IT infrastructure, businesses also gain the ability to optimize centrally. If we discover a more secure service, we can (potentially) impose it behind the scenes without expecting every team to change what they do. The platform team can continually evaluate cost, assert best-practice architectural patterns, centralize audit and observability consistently, track asset lineage for CVE response, and much more simply by centralizing and brokering changes.
Brokered ID
The most familiar use of identity brokerage is Single Sign On (SSO). SSO allows human users to sign on to a single point, indicating which contracts they wish to establish with a specific service or entity. These contracts are then brokered, or federated, across multiple systems for authentication. By leveraging SSO, a user can authenticate to a single point which then propagates that identity across multiple systems ensuring proper authentication and authorization are given to the end user, much like an individual approaching a financial broker with a request for a diversified portfolio of products.
Progressively, we recognize the necessity to broker machine identities like we use SSO for human identity. As microservices continue to drive architectural design, the requirement for applications to access multiple resources is more common. For example, an application that needs access to a database, SSH, and DataDog, can leverage an identity broker to ensure a single authentication mechanism can manage these resources. In the case of shared assets, a centralized solution becomes more critical for observability and control to monitor authenticated resources.
Let's think of manual management of secrets. The developer will request secrets for a database, their cloud provider, a service certificate for mTLS, SaaS credentials for a handful of other services, SSH, and more. If we think about brokerage, we need to think more about authorization policy and automated identity assignment based on the imposed rules.
For example, a global payments network has modern credit card transactions churning away in the public cloud but must also write batched transactions to a mainframe on-prem to drive quarterly reporting. With an identity brokerage, that JWT (JSON Web Token) coming off a Kubernetes node is vetted, and the ID broker vends/mints a new RACF credential via LDAP for the least privilege write of the batch and then flushes the credential when done. The brokered ID is delivered based on vetting the JWT, assessing policy, and implementing the change. Essentially, it drives the same behavior we implemented at the infra layer.
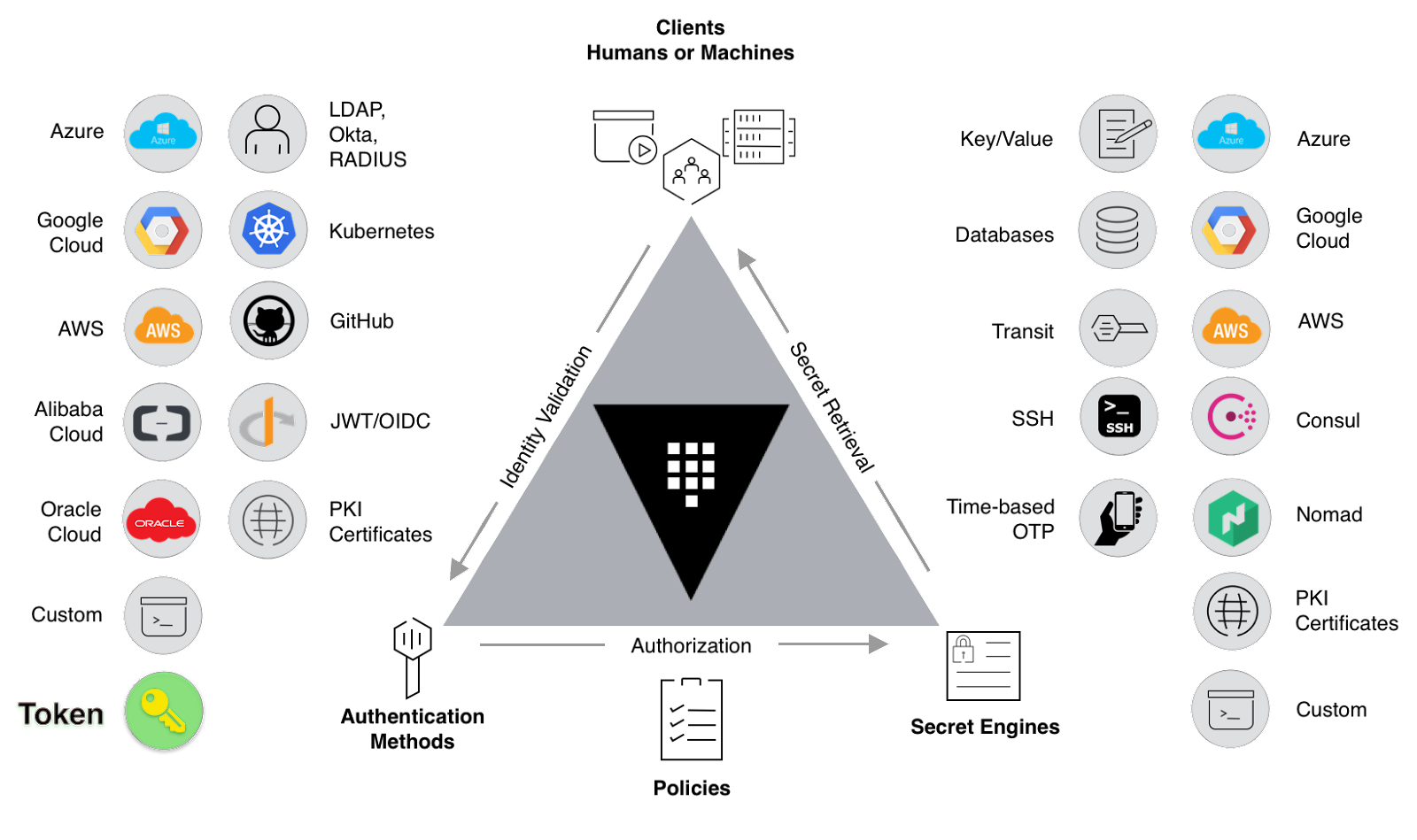
The potential impacts of this pattern are astronomical. Platform teams can assign identities dynamically based on rules and get them out of the hands of developers across the board. Given the threat of social engineering breach efforts, ID brokering reduces the threat of breach by reducing the number of credentials available to developers and operators. It also makes IT much more dynamic. We can now issue identities “just in time” as late as possible with the shortest lifespan for all identity types through a single service. The ripple effects on defense posture and audit improvement cannot be overstated.
Brokered Network
Now that we have established and trusted base infrastructure via JIT identity and automation, we turn to establish networking. While the moniker of Zero Trust has become wildly overused, it emerged in response to the vulnerability of our networks. Rather than treat some networking as “un-trusted” or “public” and other networking segments as “trusted” or “private,” we now see that no network should be treated as “trusted.” The public cloud has made us recognize that no boundary defense is 100% effective. Ergo: Zero-Trust.
Naturally, we have to establish trust somehow. Otherwise, how do we transact? Trust, then, must be established via identity and a networking rule. In the discussion above, we looked at identity brokerage, but now we turn to broker networking access based on service name coupled with identity. In service mesh land, we refer to this as a networking intention. Just as we use infrastructure code and authorization policy to drive automation above, we leverage layer seven networking intentions to drive communications in modern networking.
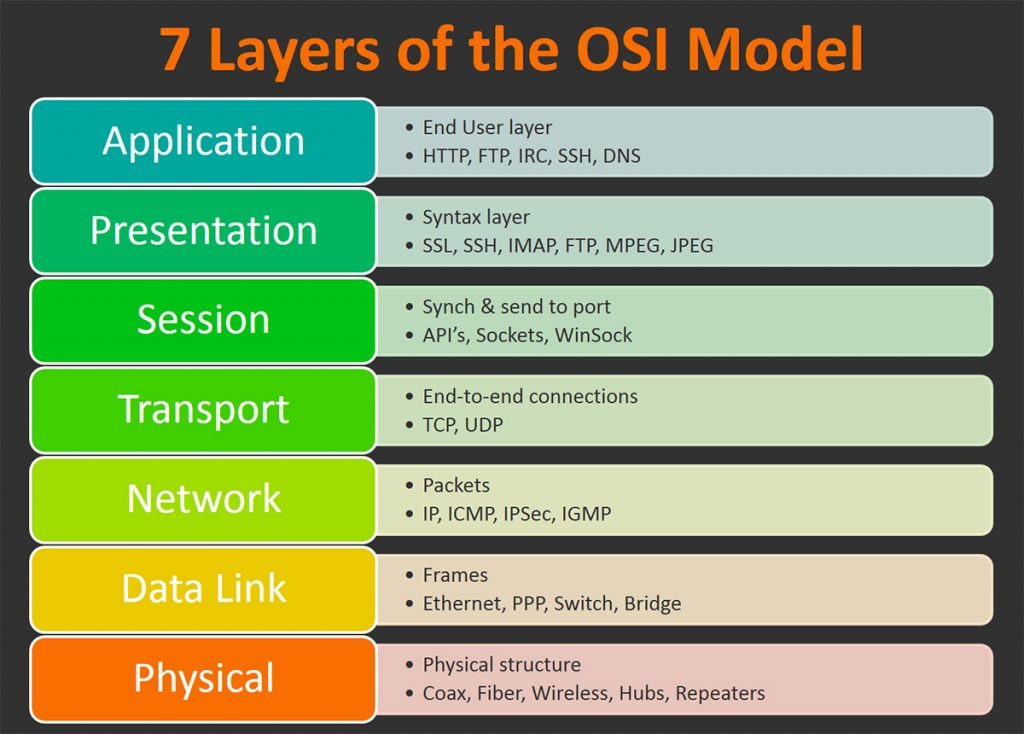
Layer 7 refers to the application layer. While much of what we do regarding networking resides in the lower levels (IP addresses for load-balancing and firewall rules, for example), these controls need more context at the application tier. They are also progressively (and wildly) ephemeral. Modern clouds are changing IPs all the time. In response, some organizations assign networking personnel to individual application teams to manage load-balancing tables. Limits to scale, then, are the number of people available for the task.
In modern microservices, the emerging pattern is one of the “service mesh.” A named service is recognized on the network, and that service’s connectivity is governed by rules we refer to as a networking intention. “Service A” can talk to “Service B” under certain conditions. Those conditions may include enforcement of mTLS or be limited by time of day (for example). The idea is that networking becomes explicitly responsive to the application requesting connectivity rather than blindly allowing traffic over known IPs.
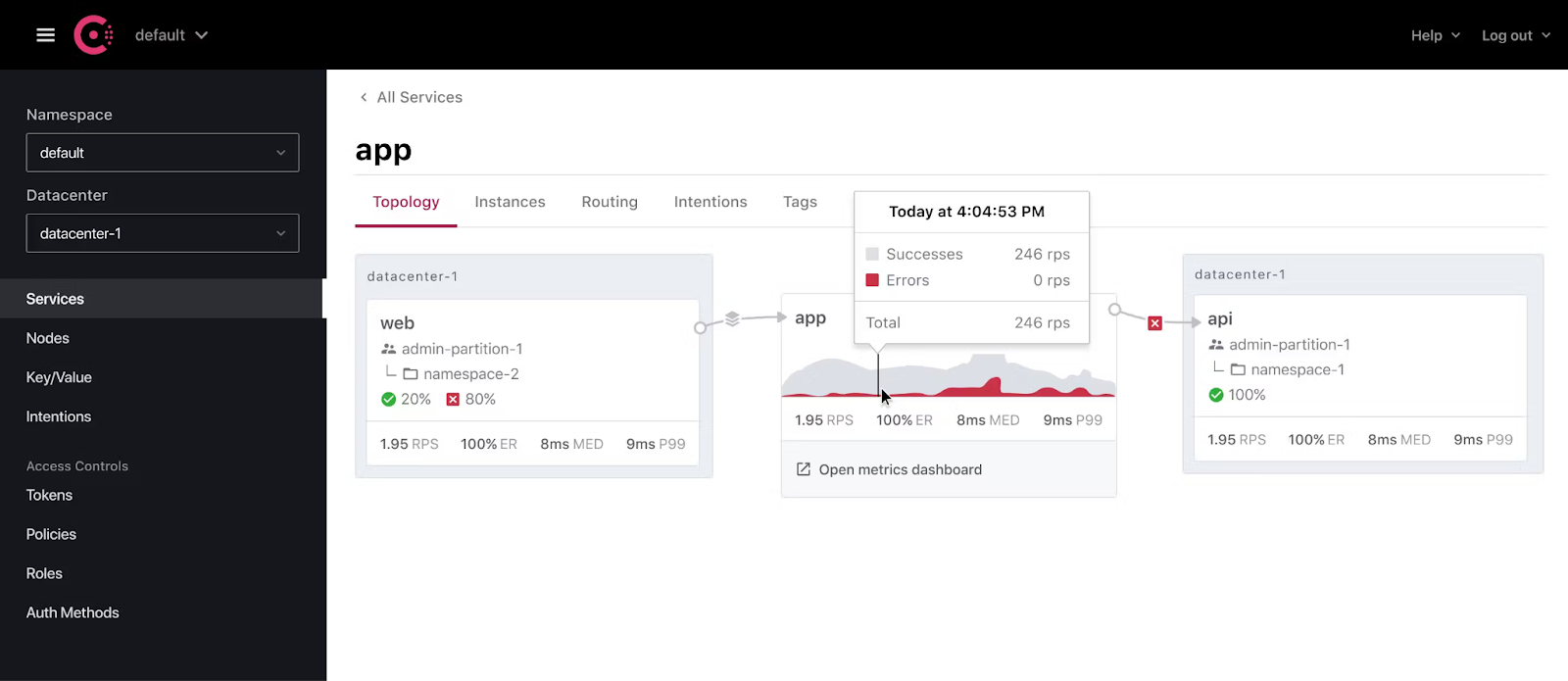
Naturally, there are IPs behind the service names, but they may be moving around quite a bit, so the stable property to base a rule around favors a name. The above picture illustrates a networking intention.
The hope is to leverage this intention to drive downstream networking automation. What happens if a cluster of EC2 instances dies and is resurrected someplace else? Not only do I want the services to be able to wire themselves back into the mesh, but I would also like to inform load-balancers and firewalls of changes they need to be aware of.
While all of these topics warrant a deeper dive, for this missive, we argue that the platform team should be able to “vend” networking in response to an intention. Similar to the above services, submit an intention, allow the team or machine to assess it for policy and security, then grant the changes based on trust. Once again, the ripple effects of such a workflow are immense. Only traffic from known and trusted services is allowed, significantly limiting network transgression opportunities for attackers, while responsiveness to change in the network is greatly improved.
Conclusion
The pattern of brokered delivery of IT is consistent with slight variations based on the kind of service being delivered (authZ policy, infrastructure code, policy code, networking intention, etc.). While we continue to go deeper into these topics, we can apply the same pattern to every aspect of IT. Application build and deployment intentions (CI/CD, PaaS, YAML), quality intentions (QA), data intentions (ETL), privileged access management (PAM), and more. The point is that without some form of “producer-consumer” model in team structure, this all becomes overwhelming at scale. The advent of a central cloud platform team structure provides a basis to extend these core services with consistency, speed, and improved quality controls (observability, audit, cost, change).
Considering your path into the multiverse of cloud madness, consider team structure and consumption patterns first. By doing so, shared responsibilities are clarified, and measures become easier to see and manage.